MySql常用命令
MySQL
MySQL常见问题
大小写敏感问题:
中文编码问题
client <-> server <-> 数据库文件
出现乱码的原因:
- Server 端使用的字符集
- client 客户端使用的字符集 (传递给客户端)
- database / table 使用的字符集
只要上面3个部分有一个使用了不支持中文的字符集就会出现乱码,注意这里并需要3个部位的编码都同时相同,因为它会自动进行转码,但是如果出现了不支持中文的字符集,那么就会转码失败,从而出现乱码问题。
比如;下面的显示结果中Server端的编码是指支持西欧语言的 latin1 字符集,当其与中文转码是就会失败,从而出现乱码。
查看编码:
SHOW VARIABLES LIKE 'character%';
输出结果:
VARIABLE_NAME | VARIABLE_VALUE
-------------------------+---------------------------------
character_set_client | utf8
character_set_connection | utf8
character_set_database | utf8
character_set_filesystem | binary
character_set_results | utf8
character_set_server | latin1
character_set_system | utf8
character_sets_dir | /usr/local/mysql/share/charsets/
| VARIABLE_NAME | VARIABLE_VALUE | 描述 |
|---|---|---|
| character_set_client | utf8 | 客户端编码设置 |
| character_set_connection | utf8 | 客户端与服务器连接编码设置 |
| character_set_database | utf8 | 当前所在的数据库字符集。如果在创建创建数据库时没有明确指定,则它和 character_set_server 一致(居然不和character_set_database相同)。 |
| character_set_filesystem | binary | 把os上文件名转化成此字符集,即把 character_set_client转换character_set_filesystem,默认binary是不做任何转换的 |
| character_set_results | utf8 | 响应给客户端数据的编码设置 |
| character_set_server | utf8 | 服务器端编码设置 |
| character_set_system | utf8 | character_set_system是个只读数据不能更改。 |
这里建议服务器端和数据库中都使用 utf8,当然其它支持中文的字符集也行,但utf8对各种语言支持的更好。
设置服务器端编码:
更改 my.cnf文件。在该文件的 [mysqld]下的character_set_server=latin1 改为 utf8。
更改database数据库的编码:
对于数据库 ,我们可以在创建数据库时就为其指定默认的编码:
create database test default CHARSET 'utf8' COLLATE 'utf8_general_ci';
也可以尝试更改现有数据库的编码:
ALTER DATABASE `db_name` DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
也可对表进行上面的操作
设置连接客户端时使用的编码:
character_set_client、character_set_connection、character_set_results这3个参数值是由客户端每次连接进来设置的,和服务器端没关系,但是可以在服务器端的配置文件(my.cnf)中设置默认值。
在客户端执行下面的语句,为当前会话同时更改上面的三个值:
set names utf8;
但是这样设置的值是临时的;可以在服务器的配置文件中为客户端设置默认值。
在服务器端为客户端设置默认值,更改配置文件中的 [mysql]下的default-character_set为utf8。
如果客户端是 cmd ,我们也可以将于客户端相关的值设置为GBK编码,配置方式与配置成 utf8 一致。
注意:客户端编辑器的字符编码问题不在该范围,比如服务器传递给客户端编辑器的编码与编辑器的编码不一致导致编辑器自身显示乱码,编辑器使用的字体不支持中文显示导致的乱码问题。
If you are using
cmd, typechcp 65001before using pandoc, to set the encoding to UTF-8.
常用的MySQL命令
这里指在系统终端或MySQL monitor中使用的命令。
在命令行中登录MySQL数据库的正确方式: 输入如下命令然后回车,接着会提示你输入密码(密码不可见)
mysql -u userName -p
(Linux中)开启/关闭MySQL服务:
# 开启
service mysql start
# 关闭
service mysql stop
# 查看服务状态
service mysql status
MySQL的帮助命令:
# 查看可通过 ? 查看的帮助种类。可用 help 代替 ?
mysql> ? contents
# 比如上面列出的种类中有 Data Types 类型,我们就可以这样查看 Data Types 的帮助
mysql> help Data Types
# 也可以直接使用 help 查看某命令的帮助,比如select
mysql> help select
参考: MySQL必知必会知识点总结一二
MySQL常用SQL语句
-- Mysql常用命令 http://www.cnblogs.com/hateislove214/archive/2010/11/05/1869889.html # 导入导出数据库、表,略 # create database dbname; # 创建数据库
-- 显示所有数据库
show databases;
-- 创建用户
create user 'fan'@'%' identified by 'Security0;';
-- 为用户授权
-- grant privileges on *.* to 'fan'@'%';
-- 添加 with grant option 选项后该用户可以给其它用户授权
-- 添加关键词all可授予全部权限
grant all privileges on *.* to 'fan'@'%' identified by 'Security0;' with grant option ;
-- 必须刷新权限
flush privileges;
-- 更改密码
alter user user_name identified by 'New_passwd4!';
-- 创建数据库;字符编码采用 utf8 那么在这个数据库下创建的所有数据表的默认字符集都会是utf8了
create database test default CHARSET 'utf8' collate utf8_general_ci;
-- 注意后面这句话 "COLLATE utf8_general_ci",大致意思是在排序时根据utf8校验集来排序
-- mysql 8 版本建议将 utf8 改为 utf8mb4
create database test default CHARSET 'UTF8MB4' collate utf8mb4_general_ci;
create database itheima default CHARSET 'UTF8MB4' collate utf8mb4_general_ci;
-- 查看所有用户,其中password_expired表示密码是否过期
select user, host,password_expired , password_last_changed , password_lifetime
from mysql.user;
-- 显示所有数据库 # drop database dbname; #删除数据库
-- 连接数据库
use test;
-- 查看当前使用的数据库
select database();
-- 查看该数据库中所有的表
show tables;
-- #### 表操作,操作之前应先连接到某个表
-- #建表,create table tbname();
-- 查看table_name的建表语句: show create table table_name;
SHOW CREATE TABLE t1;
-- 查看建表信息
DESC t1;
-- 获取表结构。同 show columns from table_name;输出结果还是有差异的。
SHOW columns
FROM t1;
/*
MySQL会话信息
*/
SHOW VARIABLES LIKE 'character%';
+--------------------------+----------------------------+
| Variable_name | Value |
+--------------------------+----------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | latin1 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | latin1 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql/charsets/ |
+--------------------------+----------------------------+
SHOW VARIABLES LIKE 'validate_password%';
+--------------------------------------+--------+
| Variable_name | Value |
+--------------------------------------+--------+
| validate_password_check_user_name | OFF |
| validate_password_dictionary_file | |
| validate_password_length | 8 |
| validate_password_mixed_case_count | 1 |
| validate_password_number_count | 1 |
| validate_password_policy | MEDIUM |
| validate_password_special_char_count | 1 |
+--------------------------------------+--------+
-- SQL的执行顺序 from... where...group by... having.... select ... order by...limit...
# TODO order by 的新发现, 它在 select 之后执行
select ename, sal/30 日薪 from emp order by 日薪;
-- 创建表
CREATE TABLE test123
(
id INT NOT NULL auto_increment,
name CHAR(40) NOT NULL,
sex CHAR(4) DEFAULT 'boy',
school VARCHAR(50) DEFAULT 'HeChi Universe',
room CHAR(10),
PRIMARY KEY (id)
)
DEFAULT charset = utf8 auto_increment = 1000;
INSERT INTO test123
(
name,
sex,
school,
room
)
VALUES
(
'徐开平',
'boy',
NULL,
-- NULL则覆盖了默认值
516
);
UPDATE test123
SET school = 'HeChi Universe'
WHERE name = '徐开平';
INSERT INTO test123
(
name,
room,
sex
)
VALUES
(
'韦大宝',
'516',
'boy'
);
SELECT *
FROM test123;
SELECT *
FROM tutorials_tb1;
INSERT INTO t1
VALUES
(
'4',
'Java nihao',
'fan',
'2006-06-11'
);
-- id 应该是自动增长的。
INSERT INTO t1
(
t1_title,
t1_author,
submission_date
)
VALUES
(
'SQL 必知必会',
'fan',
'2006-11-11'
);
-- 更新数据
UPDATE t1
SET t1_title = 'Java 编程思想'
WHERE t1_author = 'fan';
DELETE
FROM t1
WHERE t1_id = 8;
DESC t1;
-- #取表结构 # 中文乱码 # 查看当前数据库相关编码集
SHOW variables LIKE 'character%';
SET names utf8;
-- 重命名表
SELECT *
FROM test123;
rename table test123 to 516SB;
select * from 516SB order by id desc;
-- 格式化日期
select date_format(now(), '%y年%m月%d日 %H点:%i分:%s秒');
-- 自定义函数 UDF(慕课网)
create function function_name
returns
{string|integer|real|decimal}
routine_body
其中:routine_body为函数体,它可以是:
1.合法的SQL语句构成
2.可以是简单的select或insert语句
3.函数体如果为复合结构则使用 begin...end语句;
4.复合结构可以包含声明,循环,控制结构;
create function fun_date() returns varchar(30)
return date_format(now(), '%y年%m月%d日 %H点:%i分:%s秒');
select fun_date();
-- 带参数的函数
create function f2(num1 smallint unsigned, num2 smallint unsigned)
returns float(10,2) unsigned
return (num1 + num2)/2;
select f2(5,8);
-- 带复合结构的函数
-- 需要修改分隔符 delimiter //
create function adduser(username varchar(20))
returns int unsinged
begin
insert test(username) values(username); -- test是一个表,username是表的一个列。
retuen last_insert_id();
end
-- 删除函数
drop function [if exists] function_name;
自定义函数两个必要条件:
参数:可以有零个或多个
返回值:只能有一个。
分析
SQL命令 --> MySQL引擎 ------> 语法正确
|
| 编译
执行 |
客户端 <--- 执行结果 <---- 可识别的命令
-- 存储过程(慕课网)
-- 存储过程是SQL语句和控制语句的预编译集合,以一个名称存储并作为一个单元处理。;
优点:速度快;
函数有函数体,过程有过程体。过程体中可使用部分SQL语句。
过程体中语句超过1条也需使用begin end语句包围。
调用存储过程,如果没有参数则可省略括号。
为避免混淆,参数名不能与数据表中列名相同。
-- 慕课网:MySQL开发技巧 一、二、三
-- 讲的非常好。
-- 西天取经四人组表和悟空朋友表
;
use test;
create table qujin(
id int not null primary key auto_increment,
name varchar(20) not null,
over varchar(20)
);
/*
创建表的另一种形式
*/
create table pengyou
as
select * from qujin; -- 但是 id 并不会自动增长.建议不用.
drop table pengyou;
create table pengyou(
id int not null primary key auto_increment,
name varchar(20) not null,
over varchar(20)
);
-- 旃檀 (zhan tan): 指檀香
INSERT qujin (name,over) values('唐僧','旃檀功德佛'),('猪八戒','净坛使者'),('孙悟空', '斗战胜佛'),('沙僧','金身罗汉');
INSERT into pengyou (name) values('孙悟空','成佛'),('牛魔王','被降服'),('蛟魔王','被降服'),('鹏魔王','被降服'),('狮驼王','被降服');
update pengyou set over = '被降服';
update pengyou set over = '成佛' where name = '孙悟空';
select * from pengyou;
select * from qujin;
rename table qujin to a;
select * from b;
rename table pengyou to b;
/*
Join
内连接 inner 交集部分
全外连接 full outer
左外连接
右外连接
交叉连接
这里没有讲到外键
*/
;
-- 内连接 inner 应用场景用于查找交集
;
select a.name, a.over, b.over from a inner join b on a.name = b.name;
-- 无where
-- 外连接示例:
select a.name, a.over, b.over
from a left join b
on a.name = b.name;
-- 左外连接 应用场景,根据左外连接的结果排除只存在与左表但不存在与右表的值
select a.name, a.over, b.over
from a left join b
on a.name = b.name
where b.name is null; -- 条件是: 右边为null
-- 右外连接
select b.name, b.over, a.over
from a right join b
on a.name = b.name
where a.name is null;
-- 全外连接 应用场景:排除两张表的公共部分
-- MySQL不支持全外连接,可使用左外连接加右外连接再通过union all进行组合,以实现全外连接.
where a.key is null or b.key is null;
-- 实现全外连接
select a.name, a.over, b.over
from a left join b
on a.name = b.name
union all
select b.name, b.over, a.over
from a right join b
on a.name = b.name;
-- 利用全外连接,排除两表的公共部分
select a.name, a.over, b.over
from a left join b
on a.name = b.name
where b.name is null
union all -- 为什么使用 union all
select b.name, b.over, a.over
from a right join b
on a.name = b.name
where a.name is null; -- 排除了公共部分,孙悟空
-- 交叉连接: Cross Join
-- 交叉连接又称笛卡尔连接
-- 连接时没有连接关键词on
select a.id, a.name, a.over, b.id, b.name, b.over from a,b;
-- 与Join相关的SQL技巧
-- ------------------------------------------------
-- 1. 如何更新使用过滤条件中包括自身的表?
-- 情景: 把两表的公共部分的over列更新为"齐天大圣"
;
update a set over = '齐天大圣'
where a.name in(
select b.name -- 使用 a.name 都一样
from a inner join b
on a.name = b.name);
-- 这条语句在MySQL中不能执行,因为在MySQL中不能更新在from子句中出现的表
-- 在Oracle中可以.
-- 利用一个技巧: 不让出现在from从句中就让其出现在update中.
update a join ( -- 看不懂, 如果a是要更新的表,那么join是什么意思?
select b.name from a inner join b on -- 先执行括号中的select,选择出公共部分,并将结果命名为b
a.name = b.name
) b on a.name = b.name set a.over = '齐天大圣';
select * from a;
-- 2. 如何使用join优化子查询
-- 情景: 匹配出取经四人组中的人在悟空兄弟们中的结果.
-- 原查询: 速度较慢
-- 原因: 对a表中的每一行都需要进行一次子查询.(理解这一句很重要)
select a.name, a.over, (select over
from b where a.name = b.name) as over2
from a;
-- 除了慢而且怪异
-- 优化后的查询
select a.name, a.over, b.over as over2
from a left join b on a.name = b.name;
-- 3. 使用join优化聚合子查询
-- 引入一张新表,该表按日期记录四人组中每个人打怪的数量
create table user_kills(
id int primary key auto_increment,
user_id int not null references a(id),
timestr datetime not null default now(),
kills int not null check(kills > 0)
);
desc user_kills;
insert into user_kills(user_id, timestr, kills) values
(2,'2013-01-10',10),
(2,'2013-02-01',2),
(2,'2013-02-05',12),
(4,'2013-01-10',3),
(2,'2013-02-11',5),
(2,'2013-02-06',1),
(3,'2013-01-11',20),
(2,'2013-02-12',10),
(2,'2013-02-07',17);
select * from user_kills;
rename table daguai to user_kills;
commit;
-- 问题: 如何查询出四人组中打怪最多的日期?
;
select timestr,sum(kills) as kills from user_kills group by timestr order by kills desc;
select timestr ,sum(kills) from user_kills group by timestr order by kills desc;
/*
group by 与 order by
http://www.cnblogs.com/zsphper/archive/2010/06/10/mysql-group-by-order-by.html
*/
create table group_order(
id int primary key auto_increment,
name char(10) not null,
category_id int not null,
date datetime default now()
);
insert into group_order(name, category_id) values('eee',2);
commit;
select * from `group_order`;
select category_id, name from group_order group by category_id order by `date`;
select category_id, name from group_order group by category_id, name;
select * from group_order group by category_id, name, date,id ; -- 排列顺序影响结果
;
-- 再次认识group by, limit 0,2 中0代表开始行2代表行数.
select category_id, name from group_order group by category_id, date, name
order by `date` limit 0,2;
-- SQL的执行顺序 from... where...group by... having.... select ... order by... limit
-- 聚合函数忽略NULL
-- limit必须放在最后
select * from group_order where 1;
select group_concat(id order by `date` desc) from `group_order`
group by category_id;
-- 执行错误
SELECT *
FROM `group_order`
WHERE id IN (SELECT SUBSTRING_INDEX(group_concat (id ORDER BY `date` DESC),',',1)
FROM `group_order`
GROUP BY category_id)
ORDER BY `date` DESC;
-- 执行错误
select category_id from (select * from `group_order` order by `date` desc) `temp`
group by category_id order by `date` desc;
MySQL常用函数
字符串函数
- LEFT(str,len)
返回从字符串str 开始,返回最左边起的 len 个字符。
left(str,index),从index处开始截取str - RIGHT(str,len)
从字符串str 开始,返回最右边起的 len 个字符。
mysql> select right('foobarbar',4); -> 'rbar' -
LENGTH(str) 返回值为,字符串 str 的长度,测量单位为字节。一个多字节字符算作多字节。
-
CHAR_LENGTH(str) 返回值为,字符串 str 的长度,测量的单位为字符。一个多字节字符算作一个单字符。对于一个包含五个二字节字符集, LENGTH()返回值为 10, 而CHAR_LENGTH()的返回值为5。
-
CONCAT(str1,str2,…)
返回结果为,连接 str1 和 str2 后产生的字符串。如有任何一个参数为NULL ,则返回值为 NULL。或许有一个或多个参数。 如果所有参数均为非二进制字符串,则结果为非二进制字符串。 -
INSERT(str,pos,len,newstr)
返回一个字符串 ,pos 表示要插入的位置,len 表示str中要被newstr覆盖的字符数(newstr会全部插入)。 如果pos 超过字符串长度,则返回值为原始字符串。若任何一个参数为 null,则返回值为NULL。 -
INSTR(str,substr) 返回字符串 str 中子字符串的第一个出现位置。这和LOCATE()的双参数形式相同,除非参数的顺序被颠倒。如若substr 不在str中,则返回值为0。
-
LOCATE(substr,str) , LOCATE(substr,str,pos) 第一个语法返回字符串 str中子字符串substr的第一个出现位置。第二个语法返回字符串 str中子字符串substr的第一个出现位置, pos 表示判断的起始位置。如若substr 不在str中,则返回值为0。
-
LOWER(str) 返回值是字符串。以及所有根据最新的字符集映射表变为小写字母的字符 (默认为 cp1252 Latin1)。
-
UPPER(str) 返回值是字符串。 以及根据最新字符集映射转化为大写字母的字符 (默认为cp1252 Latin1).
-
REPLACE(str,from_str,to_str) 返回值是字符串。这里 from_str表示str中的某个子字符串,to_str将会替换掉from_str。就是使用 to_str 替换 str 中的 from_str 这个子字符串。
-
REVERSE(str) 字符串反转
-
TRIM([{BOTH LEADING TRAILING} [remstr] FROM] str) 返回字符串 str , 其中所有 remstr (表示要被移除的字符串) 前缀和/或后缀都已被删除。若分类符BOTH (两侧)、LEADIN (左边) 或TRAILING (右边) 中没有一个是给定的,则假设为BOTH 。 remstr 为可选项,在未指定情况下,可删除空格。
SELECT TRIM(' bar '); -- -> 'bar' SELECT TRIM(LEADING 'x' FROM 'xxxbarxxx'); -- -> 'barxxx' SELECT TRIM(BOTH 'x' FROM 'xxxbarxxx'); -- -> 'bar' SELECT TRIM(TRAILING 'xyz' FROM 'xyzbarxyz'); -- -> 'xyzbar' -
RTRIM(str) 返回字符串,结尾空格字符被删去
-
SUBSTRING(str,pos)
-
SUBSTRING(str FROM pos)
-
SUBSTRING(str,pos,len)
-
SUBSTRING(str FROM pos FOR len) 不带有len 参数的格式从字符串str返回一个子字符串,起始于位置 pos。带有len参数的格式从字符串str返回一个长度同len字符相同的子字符串,起始于位置 pos。 使用 FROM的格式为标准 SQL 语法。也可能对pos使用一个负值。假若这样,则子字符串的位置起始于字符串结尾的pos 字符,而不是字符串的开头位置。在以下格式的函数中可以对pos 使用一个负值。 注意,如果对len使用的是一个小于1的值,则结果始终为空字符串。
-
SUBSTRING_INDEX(str,delim,count)
若count为正值,则返回从左边开始遇到的第count个定界符(delim)前所包含的内容。若count为负值,则返回从右边开始遇到的第count个定界符(delim)前所包含的内容。
SELECT SUBSTRING_INDEX('www.mysql.com', '.', 2); -- -> 'www.mysql' SELECT SUBSTRING_INDEX('www.mysql.com', '.', -2); -- -> 'mysql.com' SELECT SUBSTRING_INDEX('www.mysql.com', '.', 1); -- -> 'www' SELECT SUBSTRING_INDEX('www.mysql.com', '.', -1); -- -> 'com'
字符串比较函数
还是把示例也抄下来
select 的另一个用法
日期函数
多表查询
笛卡儿积 (没关联条件)
select * from table1, table2;
内连接 (只查找有关联的数据)
select * from table1, table2 where table1.tid = talbe2.tid
外连接:
连续的两个左外连接:
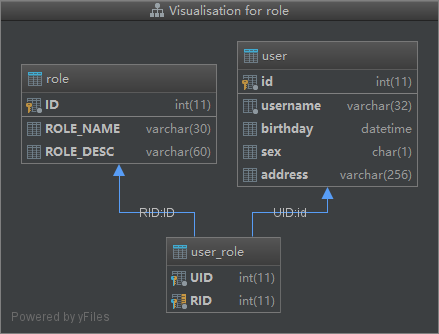
# 查询所有用户,同时获取用户的所赋予的角色
SELECT u.*,r.id AS rid,r.role_name,r.role_desc FROM USER u
LEFT JOIN user_role ur ON u.id = ur.uid
LEFT JOIN role r ON r.ID = ur.rid;
测试语句1:
# 测试
SELECT * FROM USER u LEFT JOIN user_role ur ON u.id = ur.uid;
测试语句2:
SELECT * FROM USER u LEFT JOIN user_role ur ON u.id = ur.uid
LEFT JOIN role r ON r.ID = ur.rid;
使用到的表格:
CREATE TABLE `user` ( `id` int(11) NOT NULL auto_increment, `username` varchar(32) NOT NULL COMMENT '用户名称', `birthday` datetime default NULL COMMENT '生日', `sex` char(1) default NULL COMMENT '性别', `address` varchar(256) default NULL COMMENT '地址', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; insert into `user`(`id`,`username`,`birthday`,`sex`,`address`) values (41,'老王','2018-02-27 17:47:08','男','北京'),(42,'小二王','2018-03-02 15:09:37','女','北京金燕龙'),(43,'小二王','2018-03-04 11:34:34','女','北京金燕龙'),(45,'传智播客','2018-03-04 12:04:06','男','北京金燕龙'),(46,'老王','2018-03-07 17:37:26','男','北京'),(48,'小马宝莉','2018-03-08 11:44:00','女','北京修正'); CREATE TABLE `role` ( `ID` int(11) NOT NULL COMMENT '编号', `ROLE_NAME` varchar(30) default NULL COMMENT '角色名称', `ROLE_DESC` varchar(60) default NULL COMMENT '角色描述', PRIMARY KEY (`ID`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; insert into `role`(`ID`,`ROLE_NAME`,`ROLE_DESC`) values (1,'院长','管理整个学院'),(2,'总裁','管理整个公司'),(3,'校长','管理整个学校'); CREATE TABLE `user_role` ( `UID` int(11) NOT NULL COMMENT '用户编号', `RID` int(11) NOT NULL COMMENT '角色编号', PRIMARY KEY (`UID`, `RID`), KEY `FK_Reference_10` (`RID`), CONSTRAINT `FK_Reference_10` FOREIGN KEY (`RID`) REFERENCES `role` (`ID`), CONSTRAINT `FK_Reference_9` FOREIGN KEY (`UID`) REFERENCES `user` (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; insert into `user_role`(`UID`,`RID`) values (41,1),(45,1),(41,2);
添加与修改表注释、字段注释
1 创建表的时候写注释
create table test1 ( field_name int comment '字段的注释' )comment='表的注释';
2 修改表的注释
alter table test1 comment '修改后的表的注释';
3 修改字段的注释
alter table test1 modify column field_name int comment '修改后的字段注释';
--注意:字段名和字段类型照写就行
4 查看表注释的方法
--在生成的SQL语句中看
show create table test1;
--在元数据的表里面看
use information_schema; select * from TABLES where TABLE_SCHEMA='my_db' and TABLE_NAME='test1' \G
5 查看字段注释的方法
--show show full columns from test1;
--在元数据的表里面看
select * from COLUMNS where TABLE_SCHEMA='my_db' and TABLE_NAME='test1' \G
麦子学院:MySQL基础
-- 麦子学院:MySQL
-- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- --
-- 麦子学院的这两套课程,MySQL基础课程 和 MySQL进阶课程 非常不错;并且配有Wiki(教课的完整记录)
-- MySQL教程网址:http://www.maiziedu.com/course/list/all-mysql/0-1/
-- Wiki地址:http://www.maiziedu.com/wiki/mysql/concept/
-- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- --
-- 麦子学院:MySQL基础
-- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- --
-- 只选取部分重点进行学习
-- MySQL命令行的使用技巧
开启日志: \T
以网格的形式显示,(在数据量多的时候,在输出语句后分号前添加) \G
-- 一个建表语句
CREATE TABLE [IF NOT EXISTS] tbl_name
(字段名称 字段类型 [完整性约束条件]...)ENGINE=引擎名称 CHARSET='编码方式';
-- MySQL支持的数据类型
-- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- --
一共五类数据类型:http://www.maiziedu.com/wiki/mysql/type/
1). 整数类型:
除bool,boolean其余都可分为有符号类型和无符号类型
tinyint * :2^8
smallint : 2^16
mediumint :2^26 -1
int * :2^32
bigint :2^64
bool,boolean * 等价于tinyint(1),0为false,其余为true
查看帮助的三种形式:
help tinynt;
?int
\h int
2).浮点类型 占用空间
float[(M,D)] 4字节 一般精确到小数点后7位
double[(M,D)] 8字节
decimal[(M,D)] M+2字节 定点数(精确度高不会进行四舍五入),和double一样但是其内部是以字符串形式来存储数值。
M是数字总位数,D是小数点后面的位数。
如果M和D被省略,则根据硬件允许的限制来保存值。
3).字符串类型
char(M) 定长字符串,M表示字节数0<=M<=255
varchar(M) 变长字符串,L+1个字节,L为长度,L<=M,M最大65535
tinytext
text
mediumtext
longtext
enum("value1","value2",...) 枚举类型
set("value1","value2",...) set集合,最多64个成员
4).日期时间类型
time
date
datetime
timestamp 时间戳
year 占用1字节
除year外
和日期时间有关的都是使用整型来保存时间戳以方便计算。
5)二进制类型
略
数据类型选取示例:麦子学院学员
编号:(整数:mediumint 无符号)
姓名:(字符串:varchar(20))
年龄:(整数:tinyint)
性别:(enum(‘男’,‘女’,‘保密’)
电话:(整型:int 无符号)
地址:(字符串: varchar(200))
邮箱:(字符串:varchar(50))
薪水:(浮点:float(6,2))
是否结婚:(布尔类型:tinyint(1))
-- 查看MySQL支持的存储引擎:;
show engines;
-- 显示支持的存储引擎信息;
show variables like 'have%';
-- 查看默认的存储引擎
show variables like 'storage_engine';
MySQL支持的注释:有两种
#
--
-- 测试日期时间类型(必看)
-- http://www.maiziedu.com/course/306-3350/
-- 分组查询
-- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- --
group by 按照给定列进行分组;分组后显示的结果只包含该分组中的第一行。
理解视频中group by同时按两个列进行分组后为什么显示10行数据(整个表中有12行),并且观察结果。
-- 分组查询配合聚合函数
-- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- --
-- 如何得到分组详情:
配合 group_concat()得到分组详情。即传入一个列,那么分组中的这列数据都会显示出来。
select
-- 字符串函数
-- -- -- -- -- -- -- -- -- -- -- -- -- -- --
-- 记录在MySQL必知必会的笔记中
-- 日期时间函数
-- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- --
-- 记录在MySQL必知必会的笔记中
-- 条件判断函数和系统函数
-- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- --
-- 三个条件判断函数
if(expr,v1,v2) -- 如果表达式expr成立,返回结果v1;否则v2。注意:如果expr是整型那么非零表示 true
ifnull(v1,v2)
case when exp1
then v1 [when exp2 then v2][else vn]
end
-- case表示函数开始,end表示函数结束,exp1成立则返回v1
-- 示例:
select id,username,score,IF(score >= 60, '及格','不及格') AS 是否及格
from student;
select id,username,score,
case when score > 60 then '及格' when score=60 then '好险刚及格' else '没及格' end AS 是否及格
from student;
-- 系统函数
select version(); -- 数据库版本
select connection_id(); -- 当前服务器连接数
select database(),schema(); -- 两个都是得到当前数据库名
select user(),system_user(); -- 返回当前用户
select current_user(),current_user; -- 返回当前用户
select charset('str'); -- 返回字符串str的字符集
select collation('str'); -- 返回字符串str的校验字符集
select last_insert_id(); -- 得到最近生成的auto_increment值。 常用
show global status like 'Max_used_connections';
-- 其它常用函数
-- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- --
-- 加密函数。常用前两个
-- 信息摘要算法,返回32为字符串。经常用来对密码进行加密。
select md5('str'), length(md5('str')) AS 长度;
-- 密码算法。专门为MySQL添加用户时写的密码加密。
select password('str');
-- password
use mysql;
show tables; -- 有一个user表
select * from user;
select host, user, authentication_string, password_expired, password_last_changed from user;
use test;
-- 其它
select format(3.14567, 2); -- 将数字进行格式化;这里是保存2位小数
select ascii('a');
select bin(20),oct(20),hex(20);
select conv(5,10,2); -- 指定进制转换,这里把5从10进制转换为2进制
select inet_aton(ip); -- 将ip地址转换为数字。就可以把IP地址用整型数据来存储。
select inet_ntoa(n); -- 将数字转换为ip地址
get_loct(name,time) -- 定义锁
release_lock(name) -- 解锁
-- 索引的使用
-- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- --
-- 什么是索引:
索引由数据库中一列或多列组合而成,其作用是提高对表中数据的查询速度
索引的优点是可以提高检索数据的速度
索引的缺点是创建和维护索引需要耗费时间
索引可以提高查询速度,会减慢写入速度
-- 索引的分类
普通索引
唯一索引: 比如primary key和unique是唯一索引
全文索引: 只支持英文,只能位于字符列,使用fulltext (可以使用** 代替)
单列索引
多列索引
空间索引: 用的少
;
-- 如何创建索引
-- 1)在建表的时候创建索引
;
-- 创建普通索引
create table index01(
id tinyint unsigned,
username varchar(20),
index in_id(id), -- 索引名称in_id
key in_username(username)
);
show create table index01; -- index变为 key ??
desc index01;
-- 创建唯一索引
create table index02(
id tinyint unsigned auto_increment key,
username varchar(20) not null unique,
card char(18) not null,
unique key uni_card(card)
);
show create table index02;
desc index02;
-- 创建全文索引
create table index03(
id tinyint unsigned auto_increment key,
username varchar(20) not null unique,
userDescr varchar(20) not null,
fulltext index full_userDesc(userDesc)
);
-- 创建单列索引
create table index04(
id tinyint unsigned auto_increment key,
username varchar(20) not null unique,
userDescr varchar(20) not null,
fulltext index full_userDesc(userDesc)
);
http://www.maiziedu.com/course/306-3390/
-- 2)在已经存在的表上创建索引
-- 几个省略写法:
-- 主键: primary key 可以只写 key
-- insert into 可以只写 insert
/*
补充:逻辑操作符
《SQL入门经典》第5版
is null
between
in
like
exists -- 重点介绍后面三个
unique
all 和 any
*/
;
use crash_course;
-- exists 用于搜索指定表里是否存在满足条件的记录
select * from orders;
select * from orderitems;
select * from customers;
select * from products;
-- 示例
select * from orderitems where exists (select * from orderitems where item_price > 51);
-- all 、some 和 any 操作符
-- all 用于把一个值与另一个集合里的全部值进行比较。
;
select * from orderitems where item_price > all (select item_price from orderitems where item_price < 50);
-- any用于把一个值与另一个列表里任意值进行比较。some是any的别名,它们可以互换使用。
select * from orderitems where item_price > any (select item_price from orderitems where item_price < 50);
-- 2.5的不大于任何一个所以结果中没有出现
麦子学院:MySQL进阶
# ########################################################
# 麦子学院:MySQL进阶
# ########################################################
-- 第1课: MySQL编码设定
-- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- --
-- 使用source执行sql文件中的语句
-- 查看编码格式:
show variables like "char%";
-- 1).更改服务器端编码:
如果上面的输出中 character_set_server的编码方式不为 utf8,则需要进行更改。
-- 在Windows中更改MySQL安装目录下的my.ini文件;在该文件的 [mysqld]下的
-- character_set_server=latin1改为 =utf8。更改[mysql]下的default-character_set=utf8
-- 2).更改客户端、连接、结果...编码
即更改:
character_set_client=utf8
character_set_connection=utf8
character_set_results=utf8
要在mysql命令行中或者在第三方连接工具中更改上面三个值可以直接使用命令:
;
set name 'utf8';
;
此时如果创建数据库或表的创建语句中指定了使用的字符集是支持中文的,则现在就可以插入、显示中文了
;
-- 3).更改表中的字符编码和列中的字符编码
-- 表
alter table tb_name character set utf8;
-- 列 (只更改要插入中文的列)
alter table tb_name
change col_name col_name varchar(20) character set utf8 not null;
-- 4).解决多张拥有数据的表的字符编码(表位于同一数据库中)
-- 即更改整个数据库的编码格式。
-- 解决思路:先导出整个数据库中表的结构,再导出表中的数据,然后删除原有数据库,然后再重新指定编码格式创建数据库
-- (在mysql命令行中)
-- 导出数据库中表的结构
mysqldump -uroot -p --default-character-set=utf8 -d db_name > /home/export.sql
-- 解释:导出时字符编码设置为utf8,db_name是要导出的数据库,后面是要保存建表语句的文件。
-- 导出数据库中所有表中的数据
mysqldump -uroot -p --quick --no-create-info --extended-insert
--default-character-set=utf8 db_name > /home/db_data.sql
-- 解释:--quick 快速导出;--no-create-info导出时不创建表;--en 使用多行插入;
-- 删除数据库
drop database db_name;
-- 重新创建数据库
create database db_name default charset utf8;
-- 向新创建的数据库中导入之前备份的数据
-- 先在db_data.sql文件开头添加: set name 'utf8' 避免导入时出现乱码。
mysql -uroot -p db_name < /home/db_data.sql
-- 第3课: 会话变量和全局变量
-- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- --
会话变量:单个客户端所拥有的变量。session variables
全局变量:用来配置所有客户端。 global variables
;
show variables;
show session variables; -- 默认指的就是
show session variables like 'auto%'; -- 查看该会话中autocommit是否为自动提交
set autocommit=off; -- 设置会话变量autocommit的值为关闭自动提交
show global variables;
show global variables like 'auto%';
set global autocommit=on;
-- ************** 更详细的数据导入和导出见《MySQL Cookbook 2nd 中文版》 ***********/
-- 详细的介绍“生成和使用序列” (自动增长的值) 也见该书,该书用了一章的内容介绍了序列
/*
* 备份数据
*/
-- MySQL数据库是基于磁盘的文件,普通的备份系统和例程就能备份MySQL的数据。但是由于这些文件总是处于打开和使用状态,
-- 普通的文件副本备份不一定总有效。
-- 可能解决方案:
-- 1. 使用命令行实用程序mysqldump转储所有数据库内容到某个外部文件。在进行常规备份前这个实用程序应该正常运行。
-- 2. 可用命令行使用程序mysqlhotcopy从一个数据库复制所有数据(并非所有数据库引擎都支持这个实用程序)
-- 3. 使用MySQL的backup table或select into outfile转储所有数据到某个外部文件。这两条语句都接受将要创建的文件
-- 系统名,此系统文件必须不存在。否则会出错。数据可以使用restore table来复原。
-- 首先刷新未写数据。为了保证所有数据被写到磁盘(包括索引数据),可能需要在进行备份前使用flush tables语句
-- 进行数据库维护
-- 检查表键是否正确
analyze table a;
-- 针对许多问题对表进行检查
check table a;
-- 检查自最后一次检查以来改动过的表
changed ; -- 为啥都失效了
extended;
fast;
-- 从一个表删除大量数据,回收所用的空间
optimize table table_name;
-- 查看日志文件
-- 错误日志:通常命名为 hostname.err,位于data目录中
-- 查询日志:记录了所有MySQL活动。此日志文件会变得非常大,因此不应该长期使用它。通常命名为hostname.log位于data目录,名称可以同--log命令行选项更改
-- 二进制日志:记录更新过数据(或可能更新)的所有语句。hostname-bin位于data目录。
-- 缓慢查询日志:
-- 在使用日志时,可用flush logs语句来刷新和重新开始所有日志文件
-- 改善性能
-- 见书《MySQL必知必会》
show variables like '%dir%';
-- 其中datadir的值为/var/lib/mysql/即为当前数据库文件存放目录。
-- 另外一个basedir参数表示mysql数据库的安装位置
数据备份与还原
-- 《MySQL入门很简单》 第16章:数据备份与还原
-- 数据备份
-- 数据还原
-- 数据库迁移
-- 导出和导入文本文件
-- ==== 数据备份 ======
-- 使用mysqldump命令备份
-- 该命令可以将数据库中的数据备份成一个文本文件。表的结构和表中的数据将存储在生成的文本文件中。
-- mysqldump命令的工作原理:
-- 它先查出需要备份的表的结构,再在文本文件中生成一个create语句。然后,将表中的所有记录转换成一条insert语句。
-- 命令示例:
mysqldump -u username -p dbname table1 table2 ... > BackupName.sql
-- 若省略table名则备份整个数据库。
-- 如果添加了tablename则可能导出的文件中并没有创建数据库的语句,此时该备份文件中的表及数据需还原到一个已经存在的数据库中
-- 备份多个数据库
mysqldump -u username -p --databases dbname1 dbname2 ... > Backup.sql
-- 也可以备份系统数据库 mysql
-- 备份所有数据库
mysqldump -u username -p --all-databases > Backup.sql
-- 直接复制数据库文件
-- 这样做最好将服务器先停止。如果在复制数据库的过程中还有数据写入,会造成数据不一致。
-- 这种方法对InnoDB存储引擎的表不适用;对MyISAM存储引擎的表,备份和恢复很方便。
-- 使用mysqlhotcopy工具快速备份
-- 如果备份时不能停止MySQL服务器,可以采用mysqlhotcopy工具;该工具的备份方式比mysqldump命令快。
-- mysqlhotcopy工具是一个Perl脚本,主要在Linux下操作。
-- 该工具使用lock tables 、flush tables 和 cp(命令) 来进行快速备份。但它需要安装Perl的数据库接口包。
-- 由于该工具的原理与手工复制数据库文件类似,因此该工具只能备份MyISAM类型的表。
mysqlhotcopy [option] dbname1 dbname2 ... backupDir/
-- ============ 数据还原 ===============
-- 对于使用mysqldump命令备份的文本文件;还原时可以使用MySQL命令来还原备份的数据。
mysql -u root -p [dbname] < backup.sql
-- 指定数据库名时,表示还原该数据库下的表。
-- 不指定数据库名时,表示还原特定的一个数据库。而备份文件中有创建数据库的语句。
-- 直接复制数据库目录
-- 直接复制备份的数据到MySQL的数据库目录下。此时必须保证两个MySQL数据库的主版本号是相同的;
-- 因为这样才能保证两个MySQL数据库的文件类型是相同的。
-- 使用mysqlhotcopy命令备份的数据也是通过这种方式还原。在Linux下,复制到数据库目录后,一定要将数据库的用户和组变为mysql
chown -R mysql.mysql dataDir
-- Linux下,MySQL数据库通常只有root用户和mysql用户组下的mysql用户可以访问
-- ========= 数据库迁移 =========
-- 数据库迁移是指将数据库从一个系统移动到另一个系统上。
-- 数据库迁移的原因:计算机升级、部分开发管理系统、升级MySQL数据库、换用其他数据库。
-- http://blog.csdn.net/qinxiandiqi/article/details/43270147
-- 一: 相同版本的MySQL数据库之间的迁移
-- 最常用和最安全的方法是使用mysqldump命令来备份数据库
-- 二: 不同版本的MySQL数据库之间的迁移
-- 高版本的MySQL数据库通常都会兼容低版本。
-- 最常用的方法mysqldump命令
-- 三:不同数据库之间迁移
-- 除了SQL语句存在不兼容的情况,不同的数据库之间的数据类型也有差异。
-- Windows系统下,通常可以通过MyODBC来实现MySQL与SQL Server之间的迁移。
-- MySQL迁移到Oracle时,需要使用 mysqldump 命令导出sql文件,然后手动更改sql文件中的create语句。
-- ============ 表的导出和导入 ==========
-- MySQL数据库中的表可以导出成文本文件、XML文件、HTML文件。相应的文件也可以导入到MySQL数据库中。
-- 使用select ... into outfile 导出文本文件
-- 语法形式:
select [列名] from tbname [where ] into outfile '目标文件' [option];
-- 使用mysqldump命令导出文本文件
-- 基本语法形式:
mysqldump -u root -pPassword -T 目标目录 dbname tablename [option];
-- 示例:导出test数据库下student表的记录,其中字段间用","隔开,字符型数据用双引号括起来。
mysqldump -u root -pPWD -T C:\ test student
"--fields-terminated-by=," "--fields-optionally-enclosed-by=""
-- 使用mysqldump命令还可以导出XML格式的文件"
mysqldump -u root -pPWD --xml|-X dbname tablename > C:/name.xml;
-- 用mysql命令导出文本文件
mysql -u root -pPWD -e "select 语句" dbname > C:\name.txt;
-- -e选项可以执行sql语句
-- mysql命令还可以导出XML文件和HTML文件
-- 在上面的命令基础上添加 --xml|-X (选择其一),或 --html|-H
-- 用load data infile方式导入文本文件
load data [local] infile file into table tabename [option];
-- 示例:
load data infile 'C:\student.txt' into table student
fields terminated by ',' optionally enclosed by ""; -- 指明该文件中的分隔符为',',字符串使用了'"'
-- 用mysqlimport命令导入文本文件
-- mysqlimport -u root -pPWD [-local] dbname file [option]
-- 同时也要注意分隔符问题
;;;;;;;;;;;;
序列
/**************************************************************************
* 序列(sequence)
***************************************************************************/
-- 如果使用了BDB存储引擎,在表中删除一些行之后,这些行的序列值会被重用。
-- 查看一张表使用了什么存储引擎,的方法
show table status;
show create table bug;
select engine from information_schema.tables where table_schema = 'test' and table_name = 'bug';
-- 为表更改存储引擎的方法
alter table bug engine = MyISAM;
-- 清除一张表的所有信息,并将序列计数器重新初始化
truncate table tbname;
-- ============== 查询序列值 =====================
select last_insert_id();
-- 使用max(id)的方法来查询,但该方法没有考虑到MySQL服务器多线程的特性。
-- 因为我们要考虑的是: 获得的最大值是否是你生成的。
-- 解决这个问题的方法包括,将insert和select语句合并为一个事务或者锁定表。
-- 但MySQL提供了last_insert_id()函数可以更加简洁的获取正确的id值。
-- 一个用法
select * from bug where id = last_insert_id();
-- last_insert_id()返回值基于服务器的每一个客户端连接。它避免了不同用户之间的相互干扰(这是我们需要的)。
-- 很多MySQL接口含有API扩展,它可以返回auto_increment值,而不需要执行SQL语句。
-- 服务器端和
create table booksales
(
title varchar(60) not null,
copies int unsigned not null, -- xiaoliang
primary key (title)
);
-- on duplicate key update
-- and
-- last_insert_id(expr)
insert into booksales(title, copies)
values('The Greater Trumps', last_insert_id(1))
on duplicate key update copies = last_insert_id(copies+1);
select last_insert_id();
select * from booksales;
性能优化
sql执行性能分析命令explain
用法示例:explain select * from test;
mysql> select @@MAX_CONNECTIONS AS 'Max Connections';
+-----------------+
| Max Connections |
+-----------------+
| 151 |
+-----------------+
1 row in set (0.00 sec)
mysql> show global status like 'Max_used_connections';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| Max_used_connections | 8 |
+----------------------+-------+
1 row in set (0.01 sec)
mysql> show variables like '%max_connect%';
+--------------------+-------+
| Variable_name | Value |
+--------------------+-------+
| max_connect_errors | 100 |
| max_connections | 151 |
+--------------------+-------+
2 rows in set (0.00 sec)
mysql> show full processlist;
+----+------+-----------+------+---------+------+----------+-----------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+------+-----------+------+---------+------+----------+-----------------------+
| 17 | fan | localhost | test | Query | 0 | starting | show full processlist |
+----+------+-----------+------+---------+------+----------+-----------------------+
1 row in set (0.01 sec)
group by的相关问题
MySQL 5.7 之 默认ONLY_FULL_GROUP_BY语义介绍: https://blog.csdn.net/guyan0319/article/details/79282616 https://www.aliyun.com/jiaocheng/1107229.html
MySQL 5.7.5及更高版本实现对函数依赖的检测。如果ONLY_FULL_GROUP_BY启用了 SQL模式(默认情况下),MySQL会拒绝那些select列表,HAVING条件或 ORDER BY列表所引用的查询,这些查询既不是在GROUP BY子句中命名的,也不是在功能上依赖于它们的非聚合列。(在5.7.5之前,MySQL没有检测到函数依赖,并且 ONLY_FULL_GROUP_BY默认情况下是不启用的。
而对于语义限制都比较严谨的多家数据库,如SQLServer、Oracle、PostgreSql都不支持select target list中出现语义不明确的列,这样的语句在这些数据库中是会被报错的,所以从MySQL 5.7版本开始修正了这个语义,就是我们所说的ONLY_FULL_GROUP_BY语义,例如查看MySQL 5.7默认的sql_mode如下
MySQL 5.7 之 默认ONLY_FULL_GROUP_BY语义介绍 - CSDN博客
mysql5.5迁移到5.7默认选项ONLY_FULL_GROUP_BY引发的问题 - 阿里云
MySQL5.7 group by新特性,报错1055 - CSDN博客 这里说了如何取消该特性。